Công nghệ Big Data đã đạt đến đỉnh cao trong việc thực hiện các chức năng. Bạn có thể nhận biết về chức năng, quy trình, sử dụng và tầm quan trọng của công nghệ Big Data. Tháng 8 năm 2015, Big Data đã vượt ra khỏi bảng xếp hạng những công nghệ mới nổi Cycle Hype của Gartner và tạo một tiếng vang lớn cho xu hướng công nghệ của thế giới.

Big Data là gì?
Theo định nghĩa của Gartner: “Big Data là tài sản thông tin, mà những thông tin này có khối lượng dữ liệu lớn, tốc độ cao và dữ liệu đa dạng, đòi hỏi phải có công nghệ mới để xử lý hiệu quả nhằm đưa ra được các quyết định hiệu quả, khám phá được các yếu tố ẩn sâu trong dữ liệu và tối ưu hóa được quá trình xử lý dữ liệu”.
Chúng ta hãy đào sâu hơn và tìm hiểu điều này:
Big Data là một thuật ngữ rộng cho các tập dữ liệu quá lớn hoặc phức tạp đến mức chúng khó xử lý bằng các ứng dụng xử lý dữ liệu truyền thống. Những thách thức bao gồm analysis (phân tích), capture (nắm bắt), curation (quản lý), search (tìm kiếm), sharing (chia sẻ), storage (lưu trữ), transfer (chuyển giao), visualization (trực quan hóa) và information privacy (bảo mật thông tin).
Sự tiến bộ của công nghệ, sự ra đời của các kênh truyền thông mới như mạng xã hội và các thiết bị công nghệ mới tiên tiến hơn đã đặt ra thách thức cho các nền công nghiệp khác nhau phải tìm những cách khác để xử lý dữ liệu.
Tính đến hết năm 2003, trên thế giới chỉ có khoảng 5 tỷ gigabyte dữ liệu. Cũng cùng một lượng dữ liệu như vậy trong năm 2011 tạo ra chỉ trong 2 ngày. Nhưng tính đến năm 2013, khối lượng dữ liệu này được tạo ra cứ sau mỗi 10 phút. Do đó, không có gì ngạc nhiên khi mà 90% dữ liệu của toàn thế giới hiện nay được tạo ra trong một vài năm qua.
Tất cả những dữ liệu này cực kỳ hữu ích nhưng nó đã bị bỏ bê trước khi thuật ngữ “Big Data” ra đời.
Tốc độ tăng dữ liệu
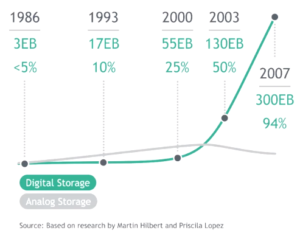
Tốc độ tăng của dữ liệu. Nguồn: BCG & IDC
Theo nghiên cứu của BCG, trong những năm 80 và 90, dung lượng lưu trữ (data storage) toàn cầu tăng đều đặn khoảng 20% mỗi năm. Thật thú vị vào thời điểm đó, hơn 95% là analog và chỉ 5% là kỹ thuật số (digital). Analog cơ bản là băng cassette, ảnh âm bản, phim chiếu rạp chiếu chiếu bóng, v.v. Sau đó một sự chuyển biến xảy ra. Kỹ thuật số bắt đầu trở thành định dạng lưu trữ mặc định cho thông tin. Trong năm 2000 dữ liệu dạng số đã chiếm 25% của tổng số thông tin được lưu trữ, vào khoảng 55 exabyte (EB), tức là 55 nghìn tỷ megabyte. Nếu bạn nhớ 3 định luật cơ bản chúng ta đã nói tới, bạn có thể dự đoán nó tiếp diễn thế nào. Rất nhanh chóng vào năm 2003, khoảnh khắc kỳ diệu mà dữ liệu số bằng với dữ liệu analog. Năm 2007, thông tin dạng số bùng nổ và chiếm tới 94% tổng dung lượng lưu trữ toàn cầu.

Data storage (lưu trữ dữ liệu)
Điều thú vị là thông tin ngày càng được lưu trữ nhiều trên máy tính, thiết bị di động, máy chủ hay địa chỉ IP và tất cả đều được kết nối toàn cầu. Nó giúp khả năng liên kết các phần thông tin khác nhau, trích dẫn, suy luận ngày càng dễ dàng và từ đó giá trị đem lại cho người dùng cũng tăng. Năm 2007, chúng ta đã có 300EB và hôm nay (2017), chúng ta đã vượt quá 4.000 EB. IDC dự đoán con số này sẽ đạt 40 zettabyte hay 40.0000 EB vào năm 2020.
Big data and analytics
Điều thực sự mang lại giá trị từ các tổ chức dữ liệu lớn là phân tích dữ liệu. Nếu không có phân tích, nó chỉ là một tập dữ liệu với việc sử dụng hạn chế trong kinh doanh.
Các doanh nghiệp đã quá quen thuộc với dữ liệu, các nhà quản lý chuỗi cung ứng đã và đang thực hiện các báo cáo, theo dõi xu hướng và dự báo trong nhiều thập kỷ qua. Vì vậy, khi dữ liệu được phát triển thành Big Data, các công ty đã nhanh chóng vượt qua thách thức trong việc thu thập nó để sử dụng trong tương lai.
Phân tích dữ liệu liên quan đến việc kiểm tra bộ dữ liệu để thu thập thông tin chi tiết hoặc rút ra kết luận về những gì chúng chứa, chẳng hạn như các xu hướng và dự đoán về hoạt động trong tương lai.
Sự phân tích có thể tham khảo các ứng dụng kinh doanh thông minh hay tiên tiến hơn, phép phân tích dự đoán như ứng dụng được các tổ chức khoa học sử dụng. Loại phân tích dữ liệu cao cấp nhất là data mining, nơi các nhà phân tích đánh giá các bộ dữ liệu lớn để xác định mối quan hệ, mô hình và xu hướng.
Phân tích dữ liệu có thể bao gồm phân tích dữ liệu thăm dò ( để xác định các mẫu và mối quan hệ trong dữ liệu) và phân tích dữ liệu xác nhận ( áp dụng các kĩ thuật thống kê để tìm ra giả thiết về một bộ dữ liệu có đúng hay không).
Một mảng khác là phân tích dữ liệu định lượng ( hoặc phân tích dữ liệu số có các biến có thể so sánh theo thống kê) so với phân tích dữ liệu định tính ( tập trung vào các dữ liệu không phải là dữ liệu cá nhân như video, hình ảnh và văn bản).
Ứng dụng

Báo cáo của Viện nghiên cứu Toàn cầu McKinsey năm 2011 mô tả các thành phần chính và hệ sinh thái của dữ liệu lớn như sau:
Các dữ liệu lớn đa chiều cũng có thể được biểu diễn dưới dạng tensor, có thể được xử lý hiệu quả hơn bằng cách tính toán dựa trên cơ sở dựa trên Tensor, chẳng hạn như nghiên cứu không gian đa cấp. Các công nghệ bổ sung đang được áp dụng cho dữ liệu lớn bao gồm cơ sở dữ liệu MPP, các ứng dụng dựa trên tìm kiếm, khai thác dữ liệu, hệ thống phân tán tập tin, phân tán cơ sở dữ liệu, điện toán đám mây và HPC (ứng dụng, lưu trữ và các tài nguyên máy tính) và Mạng Internet. Mặc dù nhiều phương thức tiếp cận cũng như các công nghệ xử lý đã được phát triển, vẫn còn khó khăn để thực hiện việc học máy với dữ liệu lớn.
Một vài cơ sở dữ liệu liên quan đến MPP có khả năng lưu trữ và quản lý hàng petabytes dữ liệu. Đó chính là một nguồn tận dụng khả năng tải về, theo dõi, sao lưu và tối ưu hóa việc sử dụng các bảng dữ liệu lớn trong RDBMS.
Chương trình Phân tích Dữ liệu Topological của DARPA tìm ra cấu trúc cơ bản của bộ dữ liệu khổng lồ và đến năm 2008, công nghệ này được công bố cùng với sự ra mắt của công ty Ayasdi.
Những chuyên viên phân tích dữ liệu lớn thường không sử dụng việc lưu trữ bằng những ổ đĩa chia sẻ vì chúng chậm, họ thích lưu trữ trực tiếp (DAS) dưới nhiều hình thức khác nhau từ ổ SSD (SATA) đến ổ đĩa SATA dung lượng cao được tích hợp bên trong các nút xử lý song song. Các kiến trúc lưu trữ dùng chung – Mạng lưu trữ (SAN) và Lưu trữ trên Mạng (NAS) tương đối chậm, phức tạp và tốn kém. Những yếu tố này không phù hợp với các hệ thống phân tích dữ liệu lớn đang phát triển mạnh mẽ về hiệu năng hệ thống, cơ sở hạ tầng và chi phí thấp.
Việc gửi thông tin thời gian thực hoặc gần với thời gian thực là một trong những đặc điểm xác định của phân tích dữ liệu lớn. Do đó độ trễ được tránh bất cứ khi nào và bất cứ khi nào có thể. Dữ liệu trong bộ nhớ là dữ liệu trên một đĩa quay tròn với một đầu kia là FC SAN. Chi phí của một SAN ở quy mô cần thiết cho các ứng dụng phân tích cao hơn rất nhiều so với các kỹ thuật lưu trữ khác.
Có nhiều lợi thế cũng như bất lợi khi sử dụng các ổ đĩa chung trong phân tích dữ liệu lớn, nhưng các chuyên gia phân tích dữ liệu lớn vào năm 2011 đã không ủng hộ chuyện này.
Công ty cổ phần giải pháp công nghệ Gadget